论文笔记:MonetDB/X100: Hyper-Pipelining Query Execution
“MonetDB/X100: Hyper-Pipelining Query Execution” 是一篇在 2005 年 CIDR 会议上发表的颇具影响力的论文,如今在 Google 上的引用量已超过860次。这篇论文主要展示了现代超标量 CPU 的运行机制,并对当时市场上主流的数据库系统在超标量 CPU 上的运行表现进行了深入的分析与实证测试。测试结果表明,市面上的主流数据库系统均未能在运行过程中充分挖掘并发挥出超标量 CPU 的全部性能潜力。正因为这个发现,作者在 MonetDB 的基础上设计并实现了一个全新的查询引擎,名为 X100。这个新型查询引擎的设计目标是为了让其能够充分利用超标量处理器的性能,从而减少每个操作在运行过程中的 CPU Cycle 数。
论文的原文地址为:MonetDB/X100: Hyper-Pipelining Query Execution。
CPU 是如何工作的
经过过去几十年的发展,CPU 已经成了一个非常复杂的器件。同样一个 CPU,高效运行和低效运行之间的性能可能有数量级的差别。下面这张图展示了过去 CPU 的发展趋势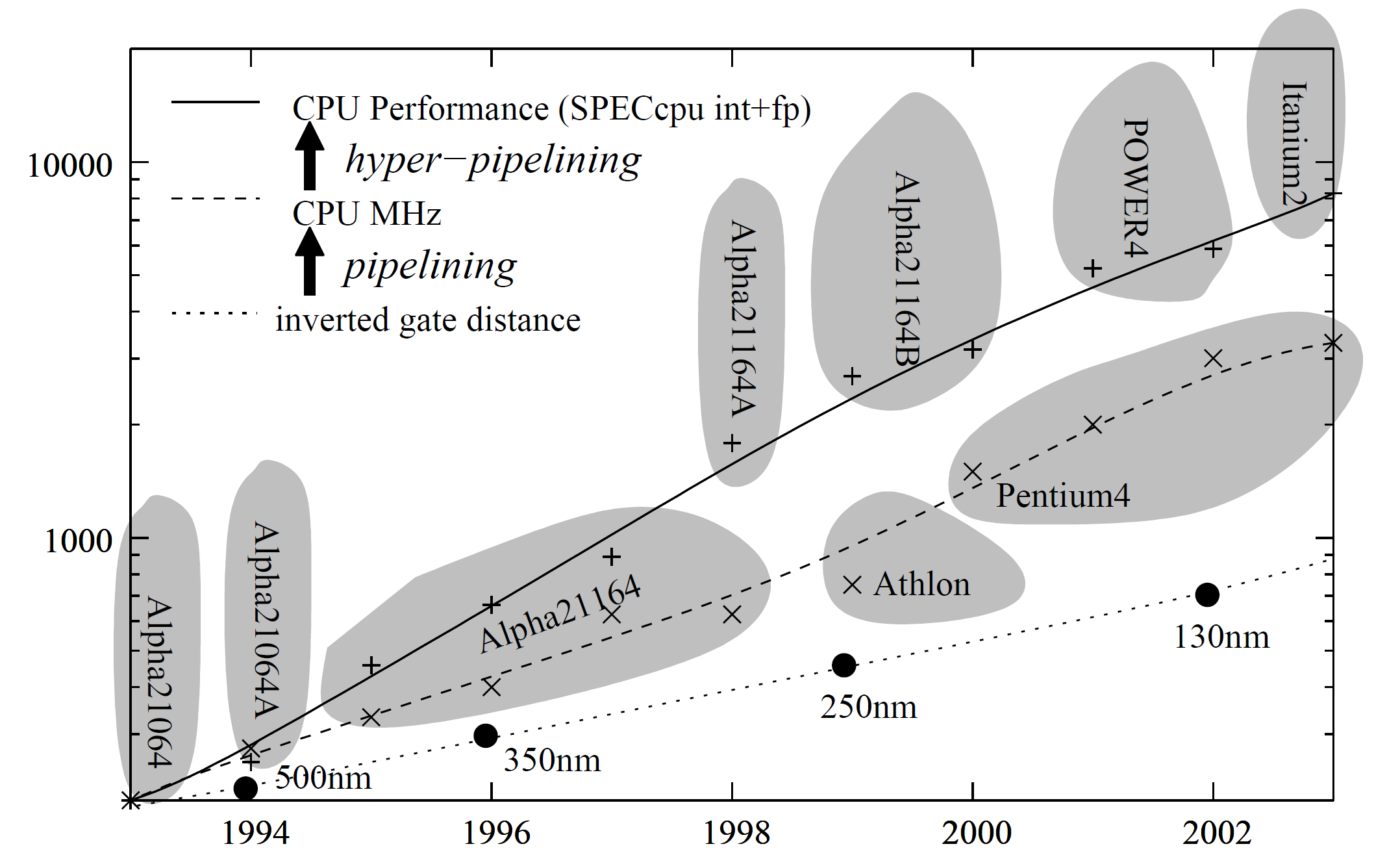
这张图是论文里的附图,上面的内容比较旧,但是我们仍然可以从中看到一些 CPU 发展的趋势。CPU 的制造工艺每隔 18 个月就缩小 1.4 倍(面积上则是 2 倍),这是 CPU 频率提升的根本原因。晶体管的大小缩小了之后,CPU 的延迟也就更低了(因为电信号传输的距离缩短了)。理论上 CPU 频率应该和延迟的倒数成正比,也就是和制程的倒数成正比,但是从上图中我们可以发现 CPU 频率的提升比制程的提升更快。这是因为 CPU 采用了流水线机制,该机制将单个指令拆分成多个阶段(stage),每个阶段需要做的工作都比一个完整的指令更少。每个阶段需要做的工作更少,也就意味着完成工作的时间更少,CPU 的频率也就越高。1988 年的 Intel 80386 CPU 每个 cycle 只完成一条指令,1993 年的 Pentium 有 5 阶段的流水线,到了 2004 年 Pentium 4 已经有 31 阶段的流水线。当然 CPU 流水线的级数并不是越高越好,我们后面会解释。到 2023 年,AMD 最新的 Zen4 架构处理器的流水线级数大约为 13-15 级(参考Edison Chen:AMD Zen 4 微架构深入测试报告),Intel 最新的 Raptor Cove 架构处理器的流水线级数为 12 级(参考Wikipedia: List of Intel CPU microarchitectures)。
然而,流水线技术也带来了两个问题:
- 如果一个指令依赖于前序指令执行的结果,那么这个指令等待前一个指令执行完成后才能执行,这会造成流水线阻塞;
- 如果遇到了一个 IF-a-THEN-b-ELSE-c 这样的分支,CPU 必须预测 a 到底是 true 还是 false,然后选择一条路径执行。例如 CPU 猜测 a 是 false,然后将 c 加入到流水线中 a 的位置之后进行执行。假如执行完了 a,发现 a 的结果是 true,也就是 CPU 的分支预测出现了错误,那么就必须将流水线清洗(flush),然后重新执行 b。
从第二个问题我们不难发现为什么流水线不是越长越好,越长的流水线在分支预测错误时被 flush 掉的损失就越大。一个 5 阶段的流水线被清洗了之后只会浪费掉 5 个 cycle,而一个 31 阶段的流水线在被清洗了以后则会浪费 31 个 cycle。对于数据库来说,分支条件通常是和数据有关的。例如一个 Filter 需要判断条件真假以过滤数据,条件通常是和数据有关的。如果条件为真的概率非常大或者非常小,那么对于 CPU 来说都会很好做分支预测。对于 CPU 来说,那些条件概率不高不低的情况对分支预测并不友好,也会带来很大的性能损失。
现代的 CPU 通常还使用了超标量技术。超标量 CPU 拥有多条独立的流水线,它们可以各自执行自己的指令。在每个 cycle 中,只要指令之间是互相独立的,每条流水线都会执行一条新的指令。因此,一个超标量 CPU 可以获得大于 1 的 IPC(Instructions Per Cycle)。所以在上面那张 CPU 发展图中,我们可以看到 CPU 的性能提升比频率的提升还要快。
现代 CPU 可以在不同的方面进行平衡。例如 Intel Itanium 2 是一个 VLIW(Very Large Instruction Word)的处理器,它拥有 6 条流水线,每条流水线的只有 7 级,所以它的频率也只有 1.5 GHz。Pentium 4 只有 3 条流水线,但是每条流水线有 31 级,频率也有 3.6 GHz。我们可以计算出,在任意时刻,Itanium2 需要程序有 $7 \times 6 = 42$ 条独立的指令才能发挥出其最大性能,而 Pentium 4 则需要 $3 \times 31 = 93$ 条独立的指令才能发挥出最大性能。这么多独立的指令是很难找出来的,大部分程序只能充分利用 Itanium 2 的并发能力,因此,尽管两者的频率差距较大,但在 benchmark 上,他们的性能相差不大。
大多数编程语言并不强制要求程序员明确指出指令间的独立性,这些任务通常由编译器自动完成。在编译器的众多优化技术中,循环流水线(loop pipelining)尤为重要。例如有两个操作,F() 和 G(),后者依赖于前者的执行结果。假如在数组 $A$ 中有 $n$ 个元素,需要对每一个元素都执行 F() 和 G(),那么指令的顺序就是
1 | |
假设 F() 需要两个 cycle 来执行,那么我们可以在 F(A[i]) 和 G(A[i]) 之间插入两个无关的指令,充分利用上这两个周期的延迟,使得指令的顺序变成
1 | |

上面这张图是作者做的一个实验,模拟一个 Filter 对数据进行过滤,并统计运行的时间。作者用同样的逻辑实现了两种代码,一种包含分支,另一种则无。结果表明,对于包含分支的代码,类似 AthlonMP 的 CPU 在选择率为 50% 左右时性能最差,这是因为此时 CPU 的分支预测错误率最高;然而,Itanium 2 的性能基本上不受选择率变动的影响,原因是编译器能将分支转化为硬件谓词化代码(hardware-predicated code)。对于没有分支的代码,即使是 AthlonMP 也不会受到选择率的影响,但是平均的运行时间却更长了。
最后要讲的一部分是 CPU 缓存。在 CPU 运行程序时,大约有 30% 的操作是对内存的 load 或者 store。因为内存与 CPU 是分开的,且通常在主板上的位置离 CPU 较远,访问内存的时间通常需要大约 50 ns。对于一个 3.6 GHz 的 CPU 来说,50 ns 代表这个 CPU 需要等待 180 个 cycle。只有当 CPU 需要访问的大部分数据都在缓存上的时候,CPU 才有可能发挥出最大的性能。有一些数据库研究者也提出了一些对缓存友好的数据结构,例如缓存对齐的 B 树(cached-aligned B-trees)、列式数据布局 PAX 等。
总的来说,由于现代 CPU 已经变得极度复杂,同样的 CPU 在运行不同程序时,由于各种因素,如缓存命中率、分支数量、分支预测准确率、无关指令数量等,性能可能相差数个数量级。研究表明,在执行查询时,一般的商用数据库的每周期指令数(IPC)只有 0.7,低于 1。然而,在科学计算这类场景中,IPC 可以达到 2 或更高。因此,作者想要改变数据库架构以充分利用编译器和 CPU 的优化和性能,提升查询的吞吐。
最后,关于 CPU 的介绍,我想推荐一篇非常不错的博客Modern Microprocessors A 90-Minute Guide,里面介绍了包括流水线、多发射、分支预测、超线程等现代 CPU 使用的技术,对理解 CPU 运行原理以及写出更好的代码有很大的帮助。
对主流数据库的测试与讨论
测试查询语句
论文关注查询执行的效率,但是为了简化,先关注表达式计算的效率,而不考虑更加复杂的操作(例如 join)。作者选择 TPC-H 的 Query 1 作为测试的基准,查询如下:
1 | |
可以看到这个查询非常简单,从一个 lineitem 表中读出数据,经过过滤后进行一系列聚合函数的计算,然后进行分组,就得到了查询的结果。执行这个查询不需要任何对 join 的优化或者复杂的实现,因此执行这个查询能够体现不同数据库计算表达式的效率。
TPC-H 基准测试在一个 1GB 的数据集上运行,其大小可以通过一个比例因子(SF)调整。Query 1 对有 $\text{SF} \times \text{6M}$ 行记录的 lineitem 表的扫描,选择几乎所有的元组($\text{SF} \times \text{5.9M}$),并计算一些定点数表达式:两个列与常数的减法,一个列与常数的加法,三个列与列的乘法,以及八个聚合函数。聚合的结果对两个单字符列进行分组,并只产生 4 个组合,因此聚合可以用一个小哈希表高效地执行,不需要额外的 IO,甚至不会造成 CPU 缓存未命中。
关系数据库上的查询
在关系数据库中,查询执行通常是实现物理关系代数来实现的,大部分数据库都使用了火山(Volcano)模型。由于 SQL 语句非常灵活,数据库需要实现一个可以处理任意复杂度的表达式的表达式解释器。使用火山模型实现这种解释器的 CPU 效率并不高,特别是使用 tuple-at-a-time 的处理方式时,真正用于计算的时间其实只占查询总执行时间的小部分。例如,下面这张表显示了在 MySQL 4.1 中执行 Query-1 时使用 gprof 进行跟踪的结果,第一列是第二列的累计总和,第三列列出了函数被调用的次数,而第四和第五列显示了每次调用执行的平均指令数以及达到的IPC。
首先观察不同部分的耗时占比。粗体的五个部分代表了真正执行计算的部分,它们只占总执行时间的 10%。剩下的时间中,其中 28% 用于哈希表的创建和查找,剩下的 62% 分散在 rec_get_nth_field 这样的函数上,这些函数在 MySQL 的数据行中找到某个 Field 并复制数据。其他的像锁开销(pthread_mutex_unlock,mutex_test_and_set)或者缓冲区内存的申请(buf_frame_align)的开销非常小。
然后观察真正执行计算部分的开销,这些部分都是以 Item 开头的部分。例如 Item_func_plus::val 每次计算一个加法,需要 38 个指令。测试是在 MIPS R12000 CPU 上进行的,理论上每个周期可以完成三个整数或浮点数的操作指令或者一个 load/store 指令,每个操作大约需要 5 个 cycle 来完成。在 RISC 中实现对 double 的加法操作 +(double src1, double src2) : double 大致如下:
1 | |
MIPS 处理器应该可以在 3 个周期内完成对浮点数的加法,这和 MySQL 中使用 38/0.8 = 49 个 cycle 完成计算的差别很大。一种可能的解释是,由于 MySQL 使用了 tuple-at-a-time 的处理方式,导致编译器进行 loop-pipelining 的优化,有依赖关系的指令只能等待前序指令执行完后再执行。但是前面提到一个指令的运行时间是 5 个 cycle,这样也只占了其中的 20 个 cycle。剩下的 29 个 cycle 主要用于指令跳转、压栈和出栈(也就是函数调用的开销)。因此,MySQL 使用 tuple-at-a-time 处理方式的后果有两个:
Item_func_plus::val只执行一次加法,阻止了编译器进行循环流水线优化。由于指令之间有依赖关系,必须生成空的流水线槽(stalls)来等待前面的指令执行结束,这样计算的时间就变为 20 个 cycle 而不是 3 个 cycle。- 函数的调用开销只能在一个 tuple 上分摊,这使得一个加法计算的成分大大增加,甚至比加法本身的代价还要高。
作者还在一个商用数据库(DBMS “X”)上进行了测试,如下表,测试的结果表明执行代价跟 MySQL 差不多。此外,表中还包含了从 TPC-H 官方测试结果中找到的数据,并且把所有的测试结果归一化到 SF=1 和单 CPU 的情况。由于测试测试条件的不同,作者还加上了测试所用 CPU 的 SPEC 分数,方便对比不同系统的表现。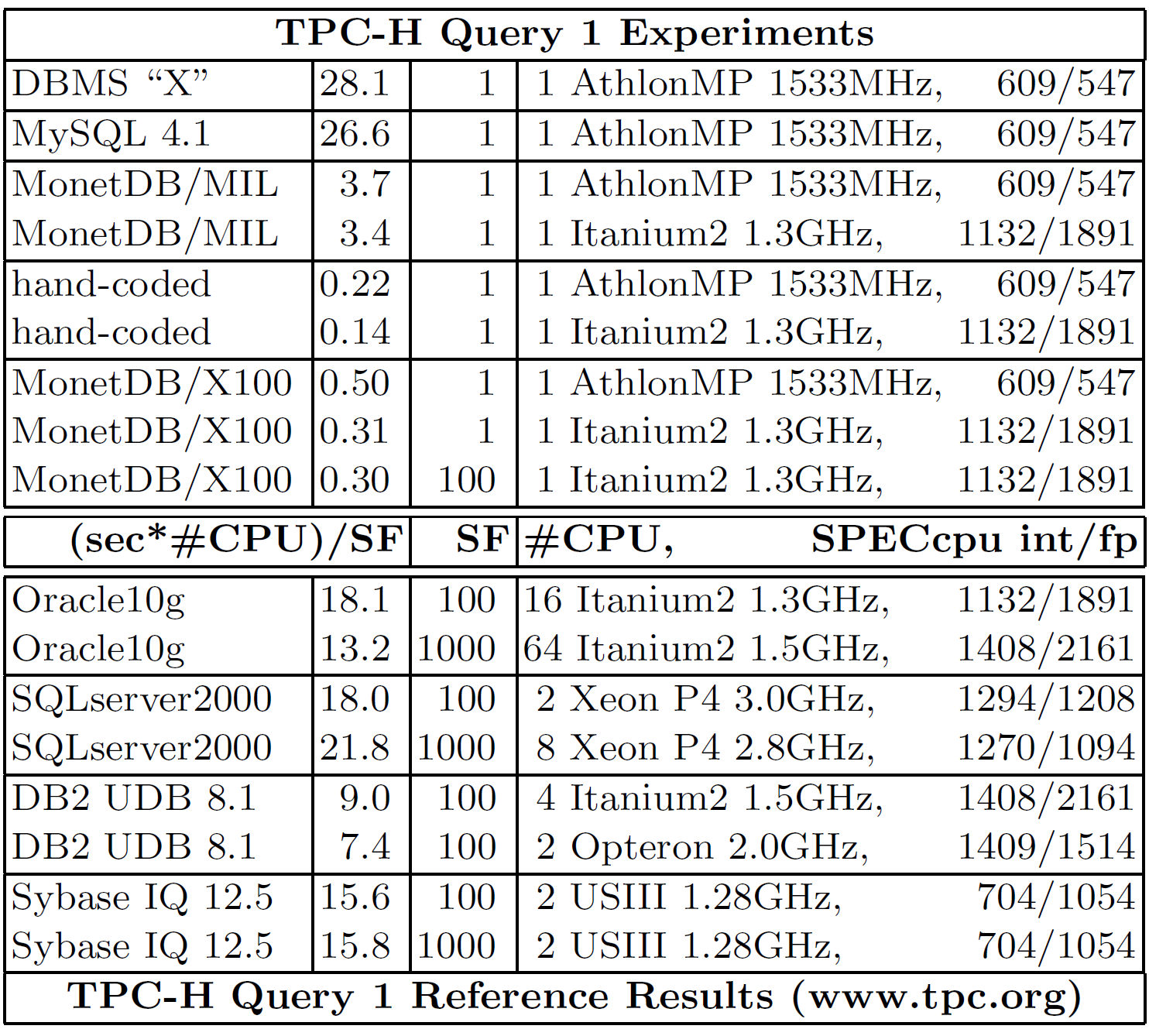
在 MonetDB/MIL 上测试 Query 1
MonetDB 是一个使用垂直分片、列式存储的数据库,每一列使用一个包含 [oid, value] 的二元关联表(Binary Association Table, BAT)来表示。BAT 的左列被称为 head,右列被称为 tail。
用于在 MonetDB 中进行查询的语言被称为 MIL,它是一种列代数(column-algebra)语言。与关系代数相比,MIL 的灵活性较低。MIL 的每个操作符都有固定数目和形状的输入参数,输出的数目和形状也是固定的。例如 $join(\text{BAT}[t_l, t_e] A, \text{BAT}[t_e, t_r] B) : \text{BAT}[t_l, t_r]$ 是一个对 A 的 tail 和 B 的 head 的等值 join,对于能够 join 上的 tuple,返回 A 的 head 和 B 的 tail。如果想要让 A 的 head 和 B 的 head 做等值 join,就需要先用 $reverse$ 操作符来调换 A 的 head 和 tail。对于复杂的操作,则需要使用多个语句来组合。
作者将 Query-1 转化为 MIL 在 MonetDB 上进行测试,结果如下: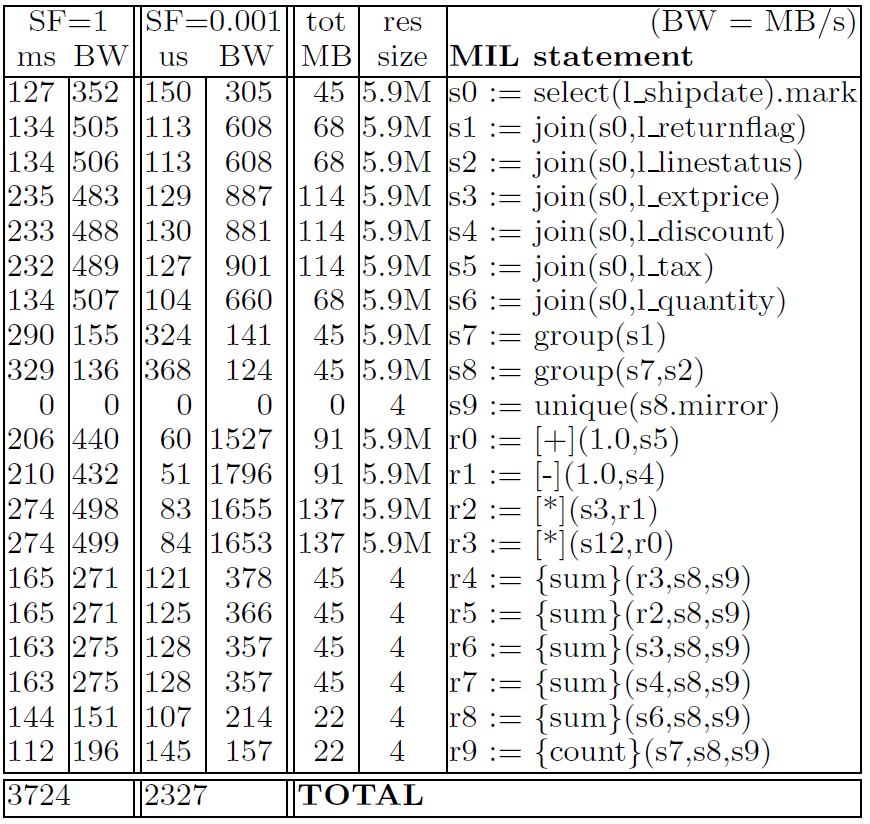
MonetDB/MIL 的性能比 MySQL 和 DBMS X 更快,但是通过深入观察可以发现,MIL 运算符的性能主要受内存限制,而不是 CPU。例如,如果我们将 SF(缩放因子)设置为 0.001,生成的 lineitem 表的所有列以及计算中间结果都可以放在 CPU 缓存中,这可以减少对内存的访问,使 MonetDB/MIL 的速度几乎加倍。同时,表中还列出了每个算子的带宽。多路复用的乘法操作 * 的带宽只有 500 MB/s,这意味着它每秒只能处理 2000w 个 tuple(每次处理的输入为 16 字节,输出为 8 字节)。在一个频率为 1533 MHz 的 CPU 上,每次乘法操作需要消耗 75 个周期,这比 MySQL 的表现还要差。
作者仔细分析了这一现象,并认为 MIL 在计算时中间结果的物化占用了大量的内存。例如,计算 sum(l_extendedprice * (1 - l_discount)) ,需要先计算 1 - l_discount,然后将结果物化到内存中;再计算 l_extendedprice * (1 - l_discount),然后将结果物化到内存中,最后才去计算 sum。最后输出的结果 sum 在两个单字符列上做了 group by,和中间结果的大小相比非常非常小。作者认为这些中间物化占用了大量的内存带宽。
此外,由于 MonetDB 使用了列式存储,每一列属性都是单独存放的。当我们对 l_shipdate 列应用条件 l_shipdate <= date ‘1998-09-02’ 进行过滤时,要使其他列也遵守这个条件,所以需要让同一个表中的其他列与 l_shipdate 列做 join。这个步骤也会消耗很多内存带宽,然而在 Volcano-like 的执行模型中却不需要这个步骤(因为使用了行存,一行数据的所有属性都放在了一起,当谓词过滤时一个行直接就被丢掉了,不需要再去 join)。
Query 1 的最优性能
为了知道现代硬件在执行 Query 1 时的极限性能,作者以 UDF 的方式在 MonetDB 中实现了这个查询,代码如下:
1 | |
BAT 以数组的形式传递给函数,并使用 restrict 指针来标记,这样 C 编译器会知道这些数组间没有重叠,从而可以采用循环流水线优化。前文测试结果的表中显示了 UDF 的性能,查询只需要 0.22 秒就能完成。同样在性能测试的结果中,X100 查询引擎实现的性能和手写代码的差距在两倍以内。下面将介绍 X100 查询引擎。
X100:一个向量化的查询处理器
X100 的目标是
- 高效地在 CPU 上执行大数据查询
- 可以在其他应用领域(如数据挖掘和多媒体检索)上扩展,并在扩展代码上实现相同的高效率
- 在最底层存储(例如磁盘)上实现拓展
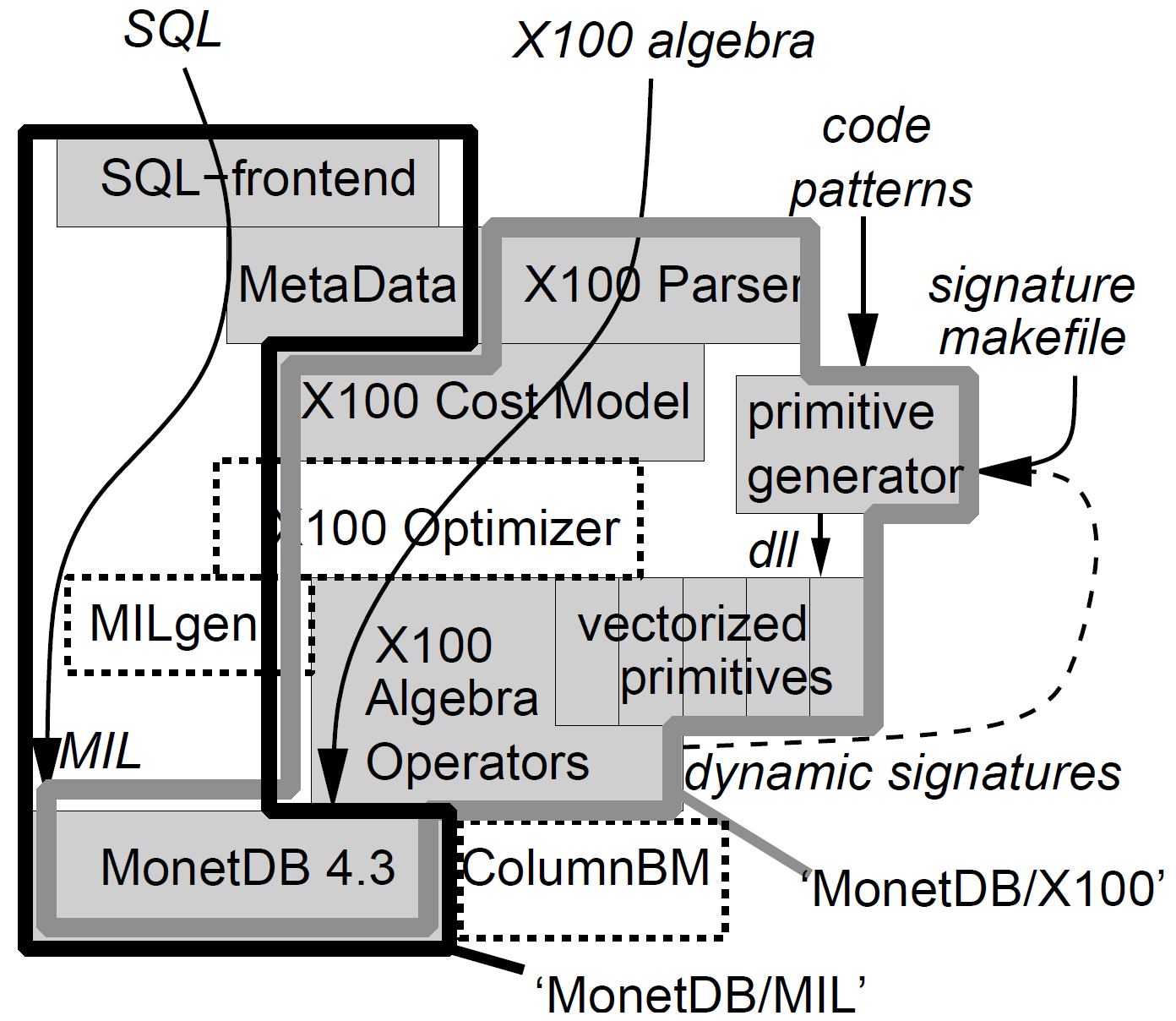
X100 的每个子系统如下:
- 磁盘:为了更高效地访问数据并且减少 IO 带宽需求,数据被垂直分片,并且在某些情况下使用了轻量的压缩。
- 内存:内存与缓存的数据交换是通过显式的 memory-to-cache 和 cache-to-memory 过程来实现的,在这些过程中实现了特定的优化,包括 SSE 预取(prefetching)和使用汇编指令来移动数据。此外,数据在内存中也进行了垂直分片和压缩,以节省内存带宽。
- 缓存: 查询执行模型使用类似于火山模型的向量化(vectorized)处理模型,小的数据块(例如 1000 个 value)被称为向量,是 X100 操作的基本单位,它可以驻留在缓存中。X100 查询处理器是缓存感知的(cache-conscious),可以将大的数据块分割成小的数据块,以可以保存在缓存里,并在缓存中进行随机访问。
- CPU:X100 的实现向编译器暴露了向量化原语(primitives),对每个 tuple 的处理都是独立的。向量化对于某些操作(如投影)来说,实现相对容易。但对于其他一些操作(如聚集函数),则需要付出更多的努力。为了减少指令中 load/store 的数量,X100 会尝试将一个表达式子树而不是单个算子编译成向量化的形式。
X100 的查询语言
1 | |
上述代码展示的是使用 X100 查询语言重写的 Query-1。在执行时,Scan 算子会从 Monet BAT 中检索数据,并包装成向量的形式。Select 算子会对数据进行过滤,它不会产生新的向量,而是会生成一个 selection-vector,用于表示向量中的哪些位上的 value 是符合条件的。然后 Project 算子计算出哪些属性是最后聚合所需要的,然后 Aggr 使用输入的向量和 selection-vector 来计算聚合值。
X100 的向量化原语
X100 之所以使用列式的向量布局,并不是出于优化内存布局的考虑,而是因为其低自由度的优点(参考前面对 MIL 的讨论)。在一个垂直分片的数据模型中,执行原语只知道它们执行的列而不需要知道整个表的布局(比如某个 field 在每个 record 中的 offset)。在编译时,C 编译器知道 X100 向量化原语只会在固定形状、互相不相关的数组上进行操作,因此就可以使用激进的循环流水线优化。例如,下面是一个向量化浮点数相加的代码:
1 | |
sel 可能为 NULL,代表这两个向量没有做任何过滤。X100 的所有向量化原语都传递了这样的 selection-vector,这是因为在 selection 之后,保持子操作符输入的向量不变比复制它们的数据然后生成一个新的向量要快得多。
在 X100 中有上百个向量化原语,这些都不是手动写的,而是从原语模板(primitive patterns)中生成的。例如加法的模板是
1 | |
此模板意味着,对于任何类型的加法运算,都可以使用 C 语言的 ‘+’ 运算符来实现。
还有一种原语的生成是通过映射签名请求(map signature requests)。例如:
1 | |
这样的请求将生成所有可能的单值与列值之间的加法组合。此外,还可以将多个操作生成在一个函数中,例如
1 | |
它代表了马氏距离的计算过程,这在多媒体检索任务中是一个非常关键的操作。作者的实验发现,组合向量化算子的性能大约是单个算子性能的两倍。造成这种现象的主要原因是计算的瓶颈通常是访存,将多个操作打包到一个函数中,只需要一次访存就可以进行多次操作,一个操作的结果可以放在寄存器中作为下一个操作的输入,减少了访存的次数,从而提高了性能。
数据布局
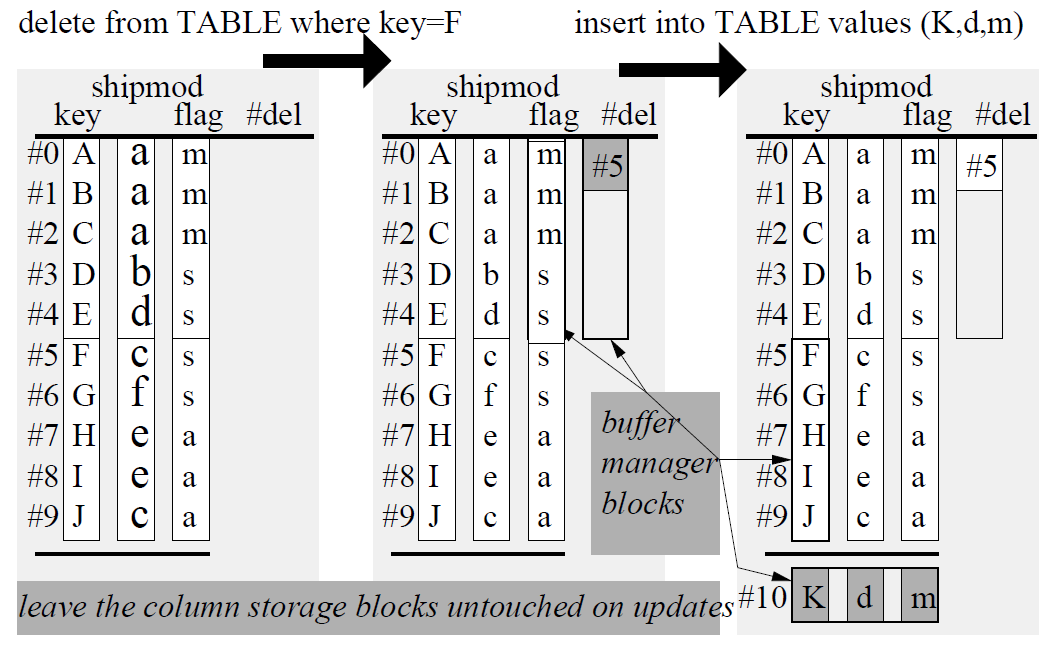
MonetDB/X100 将所有表垂直分片存储后,通过ColumnBM将每个数据文件分割成较大的数据块(大于 1MB)。列式存储的一个缺点是,更新或删除数据时较为困难,因为需要读出整个列,修改后再写回磁盘。MonetDB/X100 把列存片段当做是不变对象(immutable object),更新通过增加一个 delta structure,在 delta structure 里记录更新的数据,删除则通过维护一个 deletion list,指明列存中哪些数据已经被删除了来实现。这样做的好处就是 update 和 delete 都只需要进行一次 IO,而不用把整个列都读进来再写出去。当 delta structure 的大小超过了限制,MonetDB 就会把 delta structure 和列存数据读进内存里进行整理,然后重新写到磁盘上。
对列式存储的数据,MonetDB 还会进行轻量的压缩,以减少 IO 以及内存的使用量。同时,MonetDB 还会维护一个 summary,里面记录了列存片段的统计信息,例如最大最小值等等,以方便运行时 Scan 算子通过 summary 判断这些数据需不需要被读进来(例如需要查找 a > 100 的数据,而某个片段的 max 为 99,那么显然就不需要读这个片段)。
TPC-H 性能实验
性能测试结果
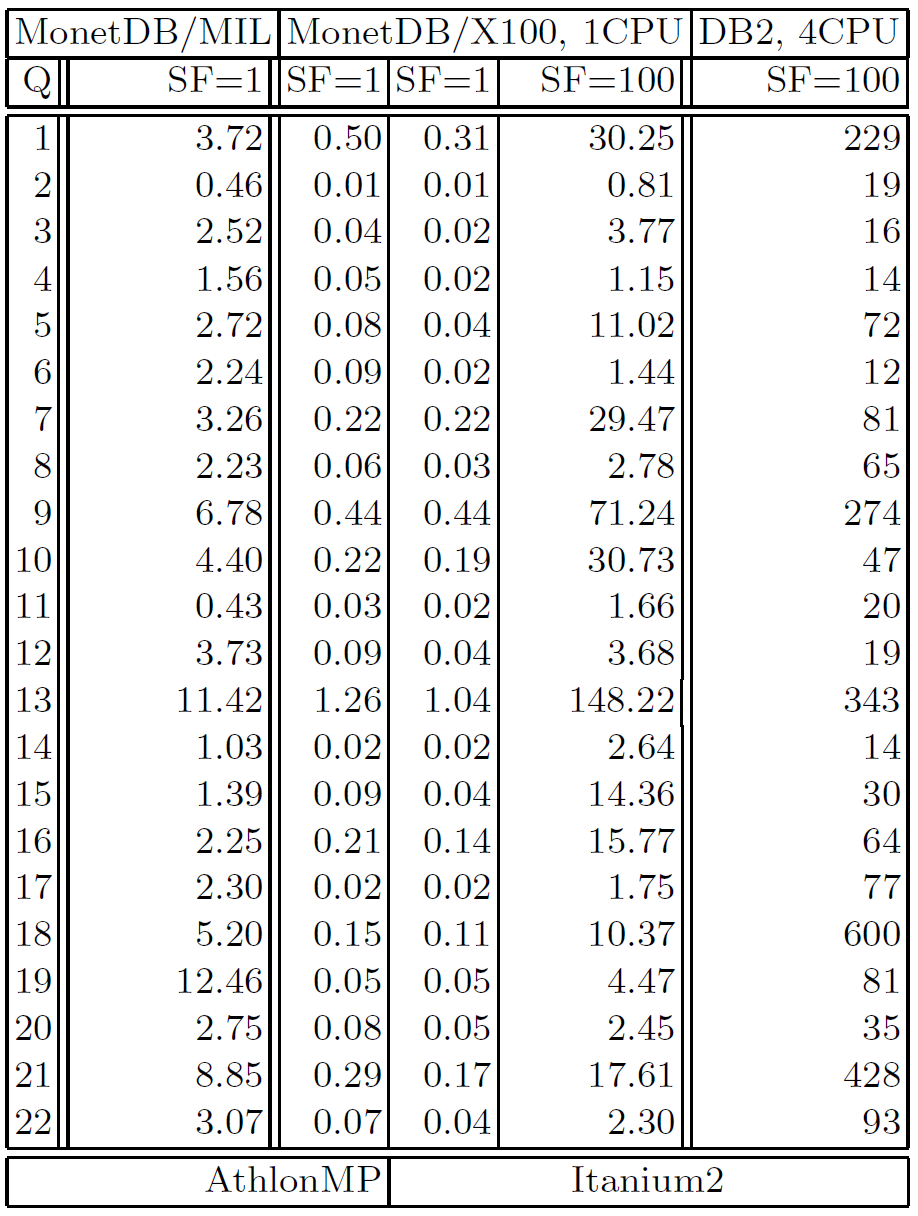
上图展示了 MonetDB/X100 与 MonetDB/MIL 和 DB2 的性能对比结果,第一和第二列的结果对比清楚地表明,MonetDB/X100的性能超过了MonetDB/MIL 和 DB2。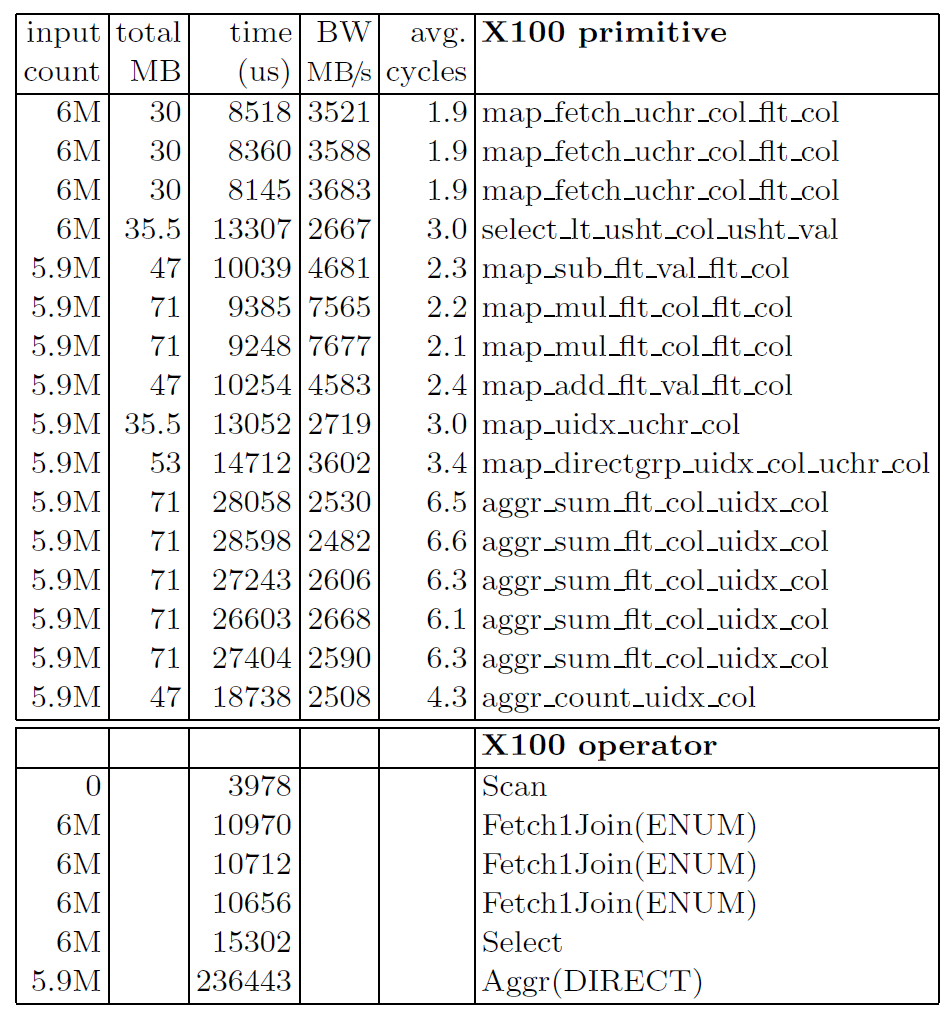
这张图揭示了 MonetDB/X100 在运行 Query 1 时的性能表现,可以看到 X100 能够用非常低 cycle 数运行所有原语,相对复杂的原语比如聚合也只需要对每个元组也只需要 6 个 cycle。对每个元组做乘法只需要 2.2 个 cycle,这比 MySQL 的 49 cycle 要好得多。
由于被原语处理的大部分数据来自 CPU 缓存中的向量,X100 能够保持非常高的带宽。在 MonetDB/MIL 中,乘法受内存带宽 500MB/s 限制,而 MonetDB/X100 在相同的运算符上超过了7.5GB/s。
向量大小对性能的影响
X100默认的向量大小是 1024,但用户可以自行调整。理想情况下,所有向量加在一起应该能刚好放进 CPU 的缓存里,因此它们不应该太大。然而,如果向量真的很小,那么计算时 CPU 的并行性就会很差。在这种情况下,X100 中 next() 方法开销会增加。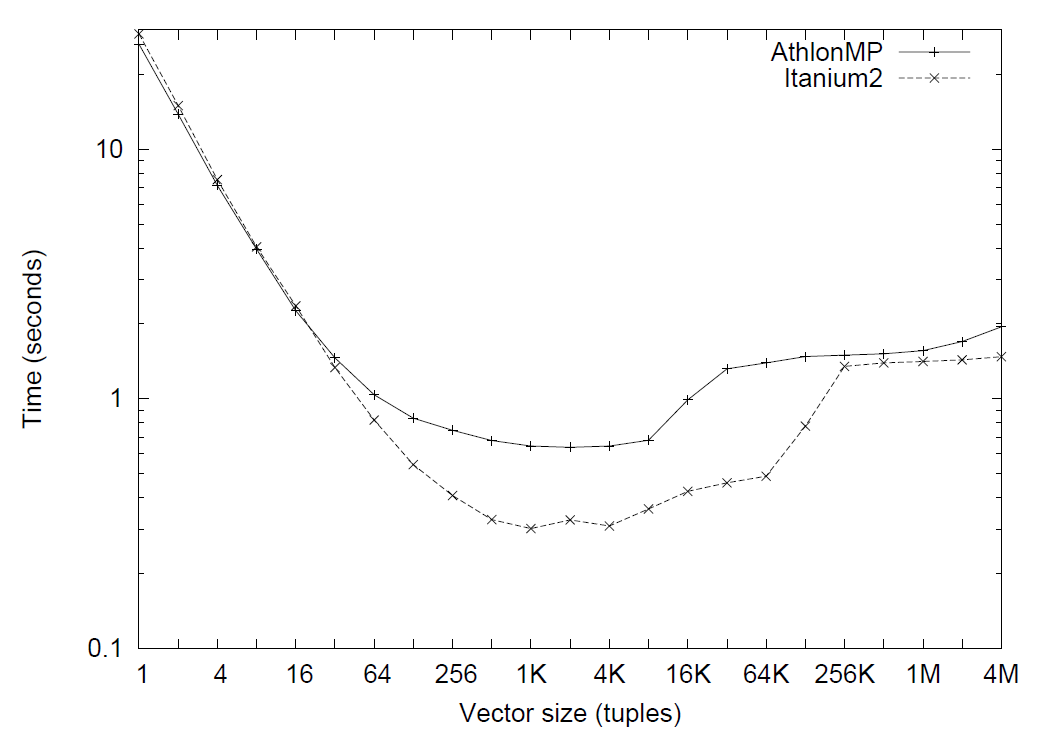
在上述实验中,研究者在 Itanium 2 和 AthlonMP 平台上执行 Query-1,并同时调整向量大小。就像 MySQL 一样,如果MonetDB/X100 使用 tuple-at-a-time 的处理模式(即向量大小为1),函数调用的开销也会严重影响到 MonetDB/X100 的性能。随着向量大小的增加,执行时间快速改善。对于这个查询和这个测试平台,最优的向量大小似乎是 1000,但实际上在 128 到 8K 之间向量大小性能都不错。当查询的中间结果不能放进缓存里时,性能开始下降。
总结
MonetDB/X100 这篇文章的背景主流数据库中每个算子计算时的 CPU cycle 数远高于理论的 cycle 数,究其原因是因为火山模型,特别是 tuple-at-a-time 的火山模型不能很好地利用现代超标量 CPU 高度并行化的特点,同时频繁的函数调用开销较大导致的。因此,作者设计了一个新的查询引擎,通过 vector-at-a-time 的执行方式减少了函数调用的平均开销,并且允许编译器进行 loop-pipelining 优化来充分利用超标量 CPU 的性能。