论文笔记:Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
Calcite 介绍
随着近些年越来越多数据处理系统的出现,出现了两个重要的问题:
- 不同系统的开发者都遇到了类似的问题,例如需要为系统提供 SQL 的支持,以及进行查询优化。每个系统都造了自己的轮子,浪费了大量的开发精力。
- 某些开发者会同时使用多个数据处理系统,例如同时使用 Flink、Elasticsearch、Druid 等。我们需要构建一个系统,可以同时访问多个数据源的查询进行优化。
Apache Calcite 就是为了解决上述问题而设计的,它是一个完整的查询处理系统,提供了查询执行、查询优化以及 SQL 适配等功能。除了数据存储和管理需要特定的系统实现,只要实现了 Calcite 规定的接口,任何数据存储系统都能基于 Calcite 做 SQL 查询。Calcite 既可以作为库被整合进数据库中作为查询引擎,也可以作为一个独立的查询系统,对多个数据源进行联邦查询。
对比其他系统,Calcite 主要有以下优势:
- 开源。Calcite 是 Apache 基金会的一个开源产品,采用 Apache License,可以轻松地在开源产品或商业产品中使用。这意味着开发者可以自由地修改和分发 Calcite,为其项目增添强大的查询处理能力。。Calcite 使用 Java 编写,其他由 Java 编写的数据处理系统(例如 Flink,以及其他 Hadoop 生态下的数据处理系统)和用 Scala 编写的系统可以很方便地集成 Calcite。
- 多数据模型。Calcite 的查询语言和查询优化不仅支持常规的数据模型,也支持对流(streaming)的优化。
- 灵活的优化器。从规则(rules)到代价模型(cost model),Calcite 优化器中的每个部分都是可以配置的。Calcite 还支持多种规划引擎(planning model),可以将查询优化分成不同的阶段,在每个阶段选择最合适的引擎。
- 支持跨系统。Calcite 支持跨多个系统的数据查询。
- 可靠性。Calcite 已经被广泛使用多年,可靠性已经被多个平台验证过。同时 Calcite 也包含了一个可拓展的测试框架来测试每一个部件。
- 支持 SQL 及其拓展。Calcite 提供了 ANSI 标准 SQL,以及多种 SQL 方言(dialects)和拓展,例如对流数据的查询。
Calcite 的架构
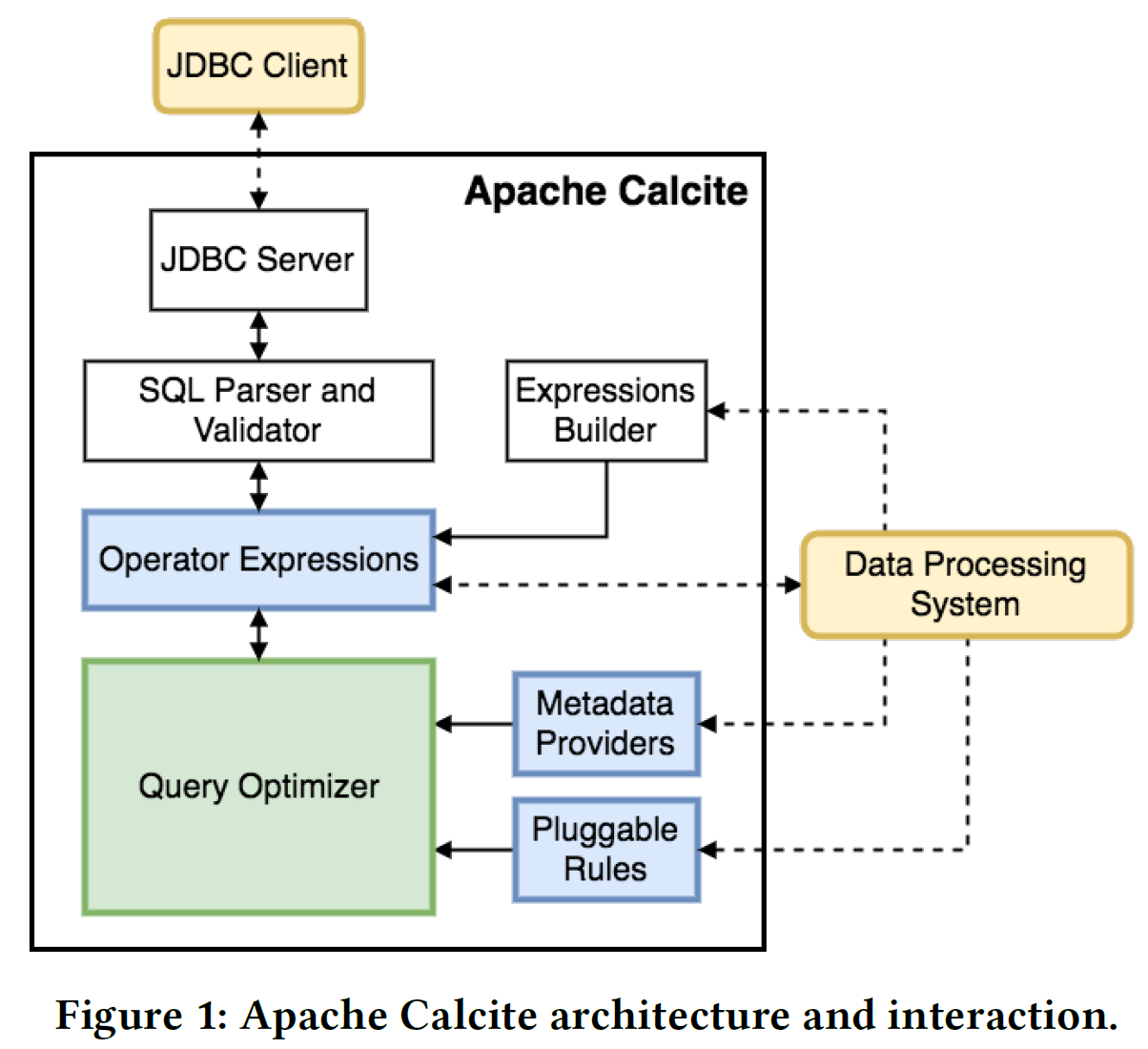
Calcite 包含了除存储引擎之外绝大多数数据库的功能,上图展示了其架构。在 Calcite 的优化器中,一个查询被表示成一个树形结构。优化器主要包含三个部分:优化规则、元数据服务(MetadataProvider)以及规划引擎(PlannerEngines),后文会对这三个模块进行更详细的介绍。上图中的虚线代表外部组件和 Calcite 之间的通信方式,外部总共有三种方式和 Calcite 进行通信:
- 客户端使用 SQL 和 Calcite 通信。Calcite 可以通过 SQL Parser 和 Validator 将 SQL 转换成一个内部的树形结构并执行。由于 Calcite 本身并不存储任何的元数据,因此需要外部引擎通过适配器(adapter)将这些信息提供给 Calcite。
- 对于一些如 Hive 这样的数据存储后端,尽管它们支持 SQL,但它们的查询优化能力相对较弱。因此,它们可能希望利用 Calcite 来完成查询优化的工作。在这种情况下,Calcite 将对客户端输入的 SQL 进行优化,然后将其翻译成特定数据处理系统支持的 SQL 方言,并将其返回给该系统以执行。
- 此外,Calcite 还允许外部系统自行完成 SQL 的解析,然后通过 ExpressionBuilder 将解析后的 SQL 构建成 Calcite 内部的表达式树,然后再进行优化。
Calcite 的查询代数
Calcite 的查询代数中,核心部件有两个:操作符(Operator)和特征(Trait)。
Calcite 支持大多数常见的关系代数算子,例如 filter, project, join 等等。除此之外,Calcite 还支持一些拓展算子,可以简洁地表示复杂的操作,或更高效地识别优化机会。例如,在 OLAP 和流处理场景中,窗口定义常被用于表示复杂的分析函数,如在一段时间或一些数据行上的计算滑动平均值。Calcite 引入了一个 window 算子,它封装了窗口定义,包括窗口的上限和下限、分区等,以及在每个滑动窗口上执行的聚合函数。
对于每种算子,Calcite 使用特征(Trait)来表示其物理属性。特征可以帮助优化器计算不同执行计划的代价。改变算子的特征并不会改变其逻辑属性。也就是说,算子输出的数据行仍然保持不变。在优化过程中,Calcite 试图在关系表达式上执行(enforce)某些特征,例如根据某些列进行排序。关系运算符可以实现一个转换器(converter)接口,表示如何将表达式的特征从一个值转换为另一个值。Calcite 包含了描述关系表达式产生的数据的常见物理属性,如排序、分组和分区。Calcite 优化器可以理解这些属性,并利用它们避免不必要操作。比如一个排序运算符的输入就是有序的(可能底层数据存储就是有序的,或者扫描的时候是根据索引来扫描的),那么这个排序运算符就可以被去除。除了常见的物理属性,Calcite 还有一个叫做 calling convention 的特征,这个特征主要描述一个表达式会在哪个数据处理系统上执行。calling convention 会被当作是一种物理属性,这使得 Calcite 可以透明地在多个存储引擎之上进行查询优化。
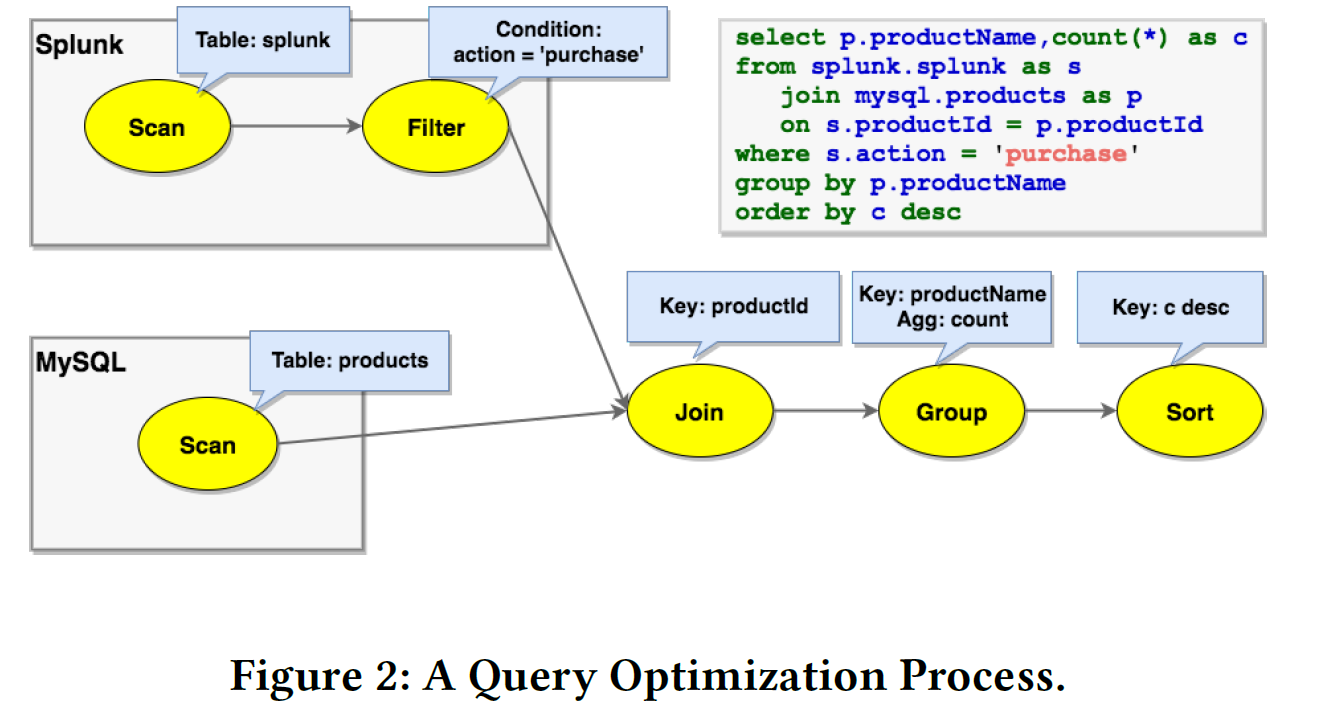
为了更好地说明 Calcite 的查询代数,论文中举了一个实际应用的例子,如下图,我们需要对 MySQL 中的 Products 表和 Splunk 中的 Orders 表做 join。初始化时,Order 表的扫描算子的 calling convention 指示这个算子会在 Splunk 上执行,Products 表的扫描算子的 calling convention 指示这个算子会通过 jdbc-mysql 执行。join 算子还是一个逻辑算子,表明系统此时没有选择这个算子的执行方式。然后,这个算子上的 where 条件会根据 adapter 中的 rule 被下推到 Splunk 中。对于 join 算子,一种可能的方式是使用 spark 作为计算引擎来执行,于是就将 join 算子的 calling convention 标记为 spark。同时,需要两个转换器,将 jdbc-mysql 和 splunk 的输入转接到 spark 中。
适配器
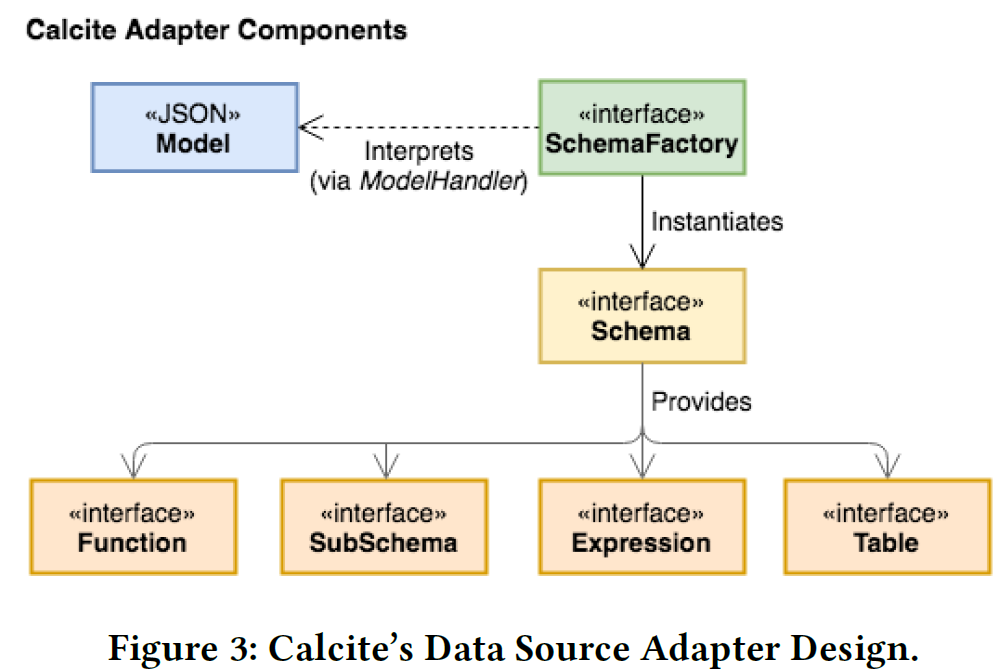
Calcite 的适配器(adapter)用于描述 Calcite 如何对各种各样的数据源进行通用访问。一个适配器包含数据模型、数据模式(schema)以及模式工厂(schema factory)。数据模型用于描述被访问的数据源的物理性质,数据模式用于描述数据的格式和布局,模式工厂负责从数据模型中获取元数据信息,生成数据模型。
查询执行时,Calcite 可以通过适配器定义好的接口从数据源中读取数据。除此之外,适配器还可以定义一些优化规则并添加到规划器中。例如,可以定义一些规则来指定如何将逻辑关系表达式转化为适配器对应的数据源上的逻辑表达式。
对于一个适配器来说,所需要实现的最小接口是对表的 Scan 接口。只要适配器实现了这个接口,Calcite 就可以自行完成 SQL 中的其他操作,例如 sort、join、filtering 等。也就是说,一个存储引擎只要提供了 scan 接口,就可以通过 Calcite 执行任意的 SQL 查询。为了充分利用并拓展适配器的功能,Calcite 还定义了一个名为“可枚举调用约定”的特性(enumerable calling convention),拥有这个属性的关系算子可以通过一个迭代器接口对数据进行逐行的操作。这个属性使得 Calcite 可以实现在每个适配器后端不支持的操作,例如 EnumerableJoin 算子可以从其子节点读取数据行然后在指定属性上执行 join。对于某些不需要读取全部数据的算子来说,将全部数据都读出来是不高效的。所以 Calcite 允许适配器定义一些规则,然后在优化的时候将 Filter 下推到后端的存储引擎中,提高执行效率。
总的来说,适配器是 Calcite 对后端数据系统的一种抽象,使得 Calcite 具有强大的灵活性,不仅可以查询一个存储系统中的数据,还可以查询跨多存储系统的数据。同时,通过在适配器中定义一些规则,Calcite 的优化器会尝试尽可能地将 Filter 下推到后端系统中,提高查询的性能。
查询优化
这一部分是 Calcite 的核心,Calcite 使用的是 Volcano 风格的查询优化器,并没有将优化分为 Rewrite 和 PhysicalOptimize 两个阶段。优化时 Calcite 通过不断地使用定义好的规则对查询所对应的关系表达式进行变换,以选出代价更低的表达式。在变换的过程中,CBO 也会参与进来指导怎么变换才是最优的。
Planner Rules
Calcite 使用一组规划器规则(Planner Rules)来对查询表达式做变换。优化时 Calcite 会在查询树中寻找对应是否有可以应用某体规则的 pattern,找到以后就将对应的规则应用到表达式上做转换。Calcite 自身已经包含了上百条查询优化的规则,同时也允许不同的系统通过适配器加入特定的规则。
例如,Calcite 提供了对 Apache Cassandra 的适配器,后者是一个宽表存储系统。在 Cassandra 中,一个表中的数据根据一组列进行分区,每个分区中的数据再根据另一组列进行排序。如果在某个查询中有排序操作,假如想要把这个排序下推到 Cassandra 中,必须满足两个条件
- 需要查询的数据在一个分区中(因为数据只在分区内有序)
- Cassandra 在分区内对数据进行排序的列和查询排序的列有共同的前缀(例如数据按照 c1, c2, c3 排序,查询要求数据 order by c1, c2, c4)
满足这些条件后就可以将表达式树中的 LogicalFilter 转换成 CassandraFilter,表示该过滤条件被下推到了 Cassandra 中执行。这样灵活的规则匹配机制使得 Calcite 在处理复杂查询的时候即可以尽可能地将过算子下推。
MetdataProvider
MetadataProvider 主要有两个目的:
- 引导 planner 选出低代价的查询计划
- 当转换规则被应用时,提供一些必要的信息
MetadataProvider 主要负责向优化器提供信息。Calcite 默认的 MetadataProvider 提供的信息包括操作符树中子表达式的代价、该表达式结果的行数和数据大小,以及表达式执行时的最大并行度。它还可以提供关于查询计划结构的信息,例如某个节点下的过滤条件。
Calcite 提供了允许外围数据系统将元数据信息插入到 Calcite 中的接口,这些系统覆写(Override)现有的函数接口来编写新的 MetadataProvider,或者提供它们可能在优化阶段被用到的新函数。对于大部分系统来说,提供输入数据的统计信息就够了(比如行数和表的大小,给定列的值是否唯一等),剩下的工作 Calcite 可以通过它的默认实现来完成。因为 MetadataProvider 是可拔插的,所以 Calcite 使用一个轻量化的 Java 编译器(Janino)来编译并实例化这些 MetadataProvider。
PlannerEngine
PlannerEngine 的目标是在输入的逻辑表达式上不断应用给定的规则,直到到达某个目标(例如代价低于某个阈值,或者优化的时间到了上限等)。Calcite 目前支持两套不同的规划引擎。
第一个引擎是一个基于代价的规划引擎,通过不断应用规则来减少表达式的整体代价。引擎的整体使用了类似于 Volcano 中的动态规划算法。优化开始,每个表达式都在 Planner 中注册,同时基于表达式的属性和其输入创建一个摘要(digest)。当一个规则应用在表达式 $e1$ 上后产生一个新的等价表达式 $e2$ 时,Planner 就会把 $e2$ 加入到 $e1$ 所属的等价表达式集合 $S_a$ 中,同时将为 $e2$ 生成一个摘要。$e2$ 的摘要将与 Planner 中已有的摘要作比较,如果发现属于集合 $S_b$ 的表达式 $e3$ 的摘要与之相似,那么 Planner 就认为 $S_a$ 和 $S_b$ 是等价的,会将其合并。这样的过程将一直持续,直到
- 搜索空间已经被穷尽,所有的规则都已经被应用过了;
- 基于启发式的停止方式,在最后一次迭代中,新查询计划的代价下降没有超过阈值 $\delta$。
Planner 计算每个候选计划的代价函数是由 MetadataProvider 提供的,默认的代价函数包含了对 CPU、IO、内存代价的估计。
第二个引擎是一个穷尽搜索(exhausetive)规划器,它将对一个表达式不断应用改写规则,直到没有任何可用的规则为止。这个引擎执行的更快,因为它无需对表达式的代价进行计算。
用户可以根据需求选择使用哪一个引擎。用户也可以选择进行多阶段(multi-stage)优化逻辑,在不同的优化阶段使用不同的规则集。
Materialized Views
数据处理系统中加速查询的一个重要手段就是对物化视图(materialized views)的预计算,Calcite 允许后端系统将物化视图暴露给优化器,这样优化器在优化时可以有机会在进行查询改写时使用物化视图来代替基表。Calcite 提供了两种对物化视图的改写算法。
第一种算法基于视图替换(view substitution),目标是将查询表达式树中的一部分使用物化视图来进行代替。算法第一步需要将物化视图的 scan 算子和物化视图的定义注册到 planner 中,第二步则是在重写阶段中通过触发改写规则将表达式树的一部分替换成物化视图。
第二种算法基于 lattices,只要数据源声明形成了一个 lattice,Calcite 就可以用 tile 来表示物化视图,并且在优化器中使用其来回应输入的查询。(这一部分没看懂)
Calcite 的拓展
这部分主要介绍了Calcite如何拓展到支持除普通关系型数据外的其他数据,包括半结构化数据(例如ARRAY、MAP、MULTISET)、流数据以及空间数据。从论文中介绍的内容来看,Caclite 拓展了标准 SQL,使得这些数据的查询和操作可以在 SQL 中进行。感兴趣的朋友可以去阅读论文的原文。
Calcite 的使用情况
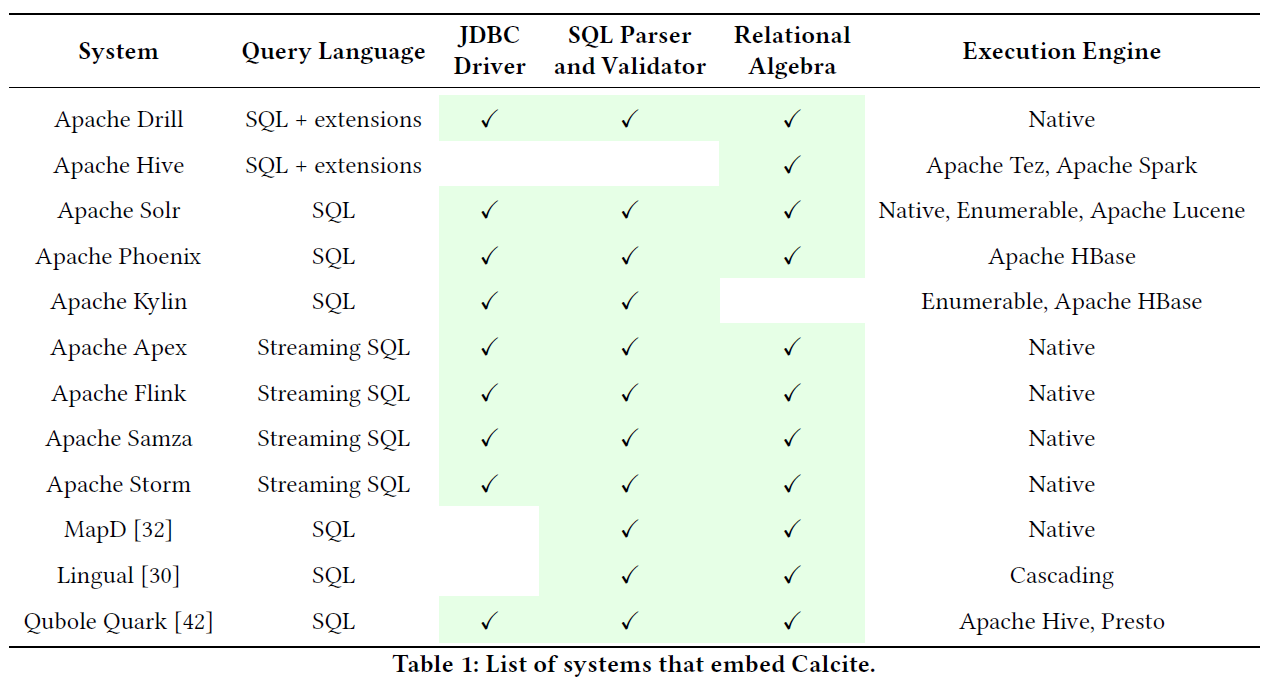
上图展示了 Calcite 作为内置优化器的各种应用场景。和 Orca 相比,Calcite 的应用还是比较广泛的。Apache 基金会下很多知名的软件比如 Hive、Flink 都使用了 Calcite 作为查询优化器。此外,一些商业软件也使用了 Calcite 作为它们的优化器。

上图展示了已实现 Calcite 适配器的各种软件,其中有一些是在大数据领域非常常用的软件,这意味着用户可以通过 Calcite 在这些软件组成的异构数据源上进行联邦查询。
总结
Apache Calcite 是一个被广泛使用的开源查询引擎,其灵活可拓展的结构让其能被各种系统轻松集成。我感觉 Calcite 想做的事情比 Orca 更多,不仅可以做一个独立的查询引擎,还可以作为优化器嵌入到不同的系统内部,节省开发的时间。在查询优化模块,Calcite 使用了类似于 Volcano 的搜索引擎,并且可以让外部系统通过实现接口加入新的优化规则以及实现新的代价函数,提供了良好的拓展性。在查询执行上,只要后端系统提供一个 Table Scan 接口,Calcite 就可以在这个系统之上执行任意的 SQL 语句。这意味着只要我们能够做好其他数据模型到关系型模型的抽象,例如将 KV 模型映射到关系型模型,就可以通过 Calcite 向用户提供 SQL 的执行能力,这一点我觉得还是非常厉害的。