论文笔记:The MemSQL Query Optimizer: A modern optimizer for real-time analytics in a distributed database
最近暑期实习的工作是和 MySQL 的查询优化器相关。过去我在 IoTDB 所做的工作主要和存储引擎相关,对于查询的了解仅限于火山模型,对查询优化的了解仅限于知道有 RBO 和 CBO。对于暑期工作的内容,我基本上需要从头开始学。我学习查询优化主要方式包括论文阅读、网络上的公开课和讲座(CMU 15-721 以及 CMU Database Group 关于 Query Optimizer 的系列讲座)以及数据库查询优化器的源代码阅读(主要是 MySQL)。目前为止看了大概有六七篇论文,对查询优化器有了一些初步的概念。有些时候我看完论文再过一段时间,就会记不清楚论文讲的一些东西了。所以我决定写一些阅读笔记来记录一下自己看的这些论文,也方便和大家的交流学习。因为在查询优化器领域我算是刚刚入门,所以论文里有些地方我可能理解的不对,如果有错误之处希望各位读者及时指出。
这篇论文发表在 VLDB 2016 上,原文链接为:https://vldb.org/pvldb/vol9/p1401-chen.pdf
MemSQL 简介
MemSQL 是一个分布式的、针对内存优化的数据库,擅长大规模混合实时分析和事务处理。MemSQL 在内存里用行式存储,在磁盘上使用列式存储,查询的时候可以从这两种不同格式的数据源中获取数据。MemSQL 利用了 MVCC 和针对内存优化的无锁数据结构来增加读写的并发度,从而实现了对运营数据库的实时分析。MemSQL 的设计目标是在通用计算机上进行拓展,而不需要任何特定的硬件或者指令集。
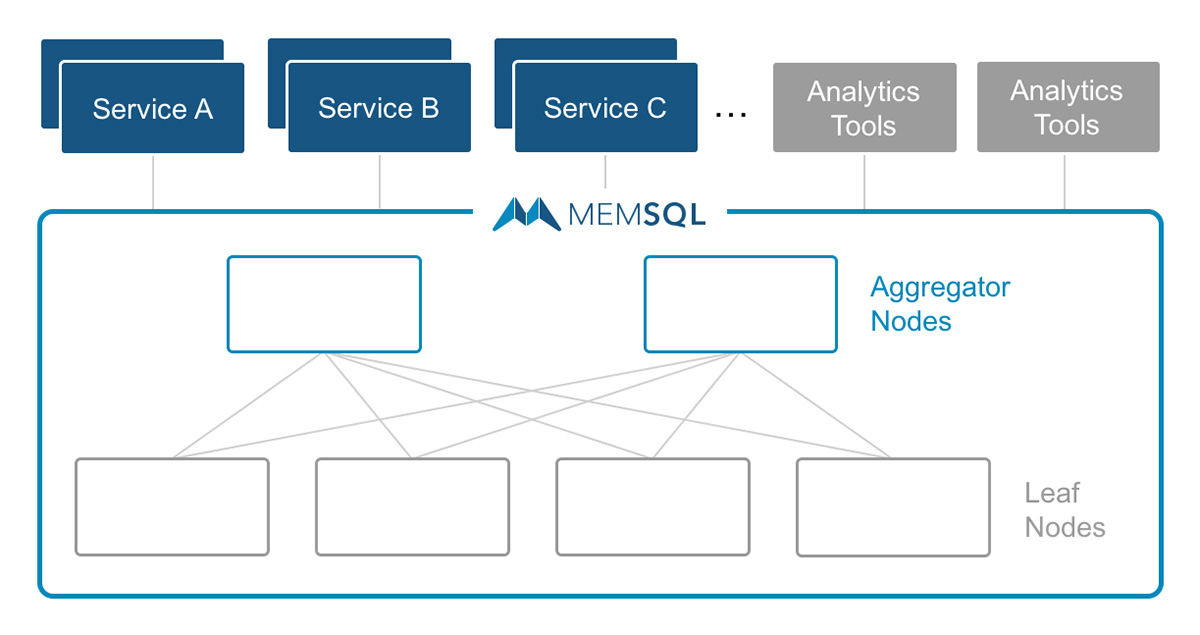
MemSQL 的分布式架构是 Share-Nothing 架构,集群中的节点分为调度节点(aggregator nodes)和执行节点(leaf nodes)。前者的作用是作为集群和客户端之间的中介,后者则负责存储数据和执行查询。用户的查询时,查询会先发到调度节点上,被解析、优化和规划(planned)之后发送到执行节点上执行。
MemSQL 中的数据有两种分布方式,一种是对表中的每一行都根据 shard key 进行哈希,即水平分片;另一种则是对表中的内容在集群中的所有节点都进行复制。为了在集群中执行一个查询,调度节点会把 SQL 转换成一个分布式查询计划(DQEP)。一个 DQEP 里包含很多步骤,每一个步骤可以用 SQL-Like 的语法进行描述。为了描述 DQEP 中的内容,MemSQL 对标准 SQL 继续进行了拓展,往其中加入了 RemoteTables 和 ResultTables 两个关键字。
查询计划生成后被编译成机器代码并且缓存起来,以加速后续查询的执行。MemSQL 不会缓存查询的结果,只缓存查询的计划。在编译查询计划时没有指定预设参数的值,因此后续查询的参数不同也可以利用前面缓存住的查询计划。
MemSQL 的优化器
MemSQL 上运行的很多查询都是复杂的实时分析型查询,包括星型模型和雪花模型下的 join、排序、分组、聚集查询以及嵌套子查询等等。MemSQL 的优化器不仅要找到一个高质量的查询计划,还要保证执行查询优化本身的时间不能太长。这是因为 MemSQL 的查询延迟都需要在秒级甚至更短,如果查询优化本身的开销很大就会导致其成为查询延迟中显著的一部分。
对分布式数据库开发一个优化器是一个很难的任务,如果使用已有的查询优化器,可能无法完成前面所述的目标(高质量且耗时短),并且还会继承已有优化器的所有缺点。因此,MemSQL 决定自己从头造一个优化器。
MemSQL 的优化器主要包含以下几个组成部分:Rewriter、Enumerator 和 Planner。下面我们逐一进行介绍。
Rewriter
基于分布式代价的查询重写
Rewriter负责对查询进行等价的逻辑转换。MemSQL 的 Rewriter 把变换规则分为了两类,一类是启发式规则,即无需进行代价判断就可以直接使用规则,例如列消除(Column Elimination),一定可以减少系统的 IO 和计算;另一类是基于代价的规则,这种规则使用之后不一定可以给查询带来性能优化,所以需要通过代价来判断到底是不是有益的。例如对于一个带有多表 join 的视图,如果将它展开到上层查询中,就会在上层查询中出现一个特别大的 join,对于 Enumerator 来说比较难优化。此外,将子查询展开到上层会使得子查询在连接图(join graph)中的结构信息消失,这些结构信息对在对 join 进行优化时可能是有用的。因此,是否对子查询进行展开需要通过 cost 来判断。
Rewriter 通过 Enumerator 来计算候选查询计划的代价。由于 Rewriter 中的每条规则通常只会对一整个查询中的一部分进行修改,其他部分往往保持不变,为了减少 Enumerator 计算的开销,Enumerator 只会计算 Rewriter 改变的那一部分的代价,对于查询中其他不变的部分则不进行计算。在计算一个查询计划的代价的时候,不仅需要考虑到在单机上执行的代价,还要考虑到在分布式条件下不同节点之间数据传输的代价,这一点作者在文中有反复提到,并且给了一个例子来说明考虑数据分布代价和不考虑数据分布代价之间的区别。例如,有下面两条 SQL,它们之间是等价的:
1 | |
假设 T1 表的行数为 $R_1 = 200,000$,T2 的行数为 $R_2 = 50,000$,对 T1.a, T2.b 进行 Group By 的过滤率为 $S_G = \frac{1}{4}$ ,对 T1.a = T2.a 进行 join 之后的过滤率为 $S_J = \frac{1}{10}$,并且假设 $S_G$ 和 $S_J$ 是独立的。假读取 T2.a 中的每一行的代价是 $C_J = 1$,对每一行数据使用哈希表计算 Group By 的代价是 $C_G = 1$,那么 Q1 和 Q2 的代价分别是$Cost_{Q1}=R_1C_J + R_1S_JC_G = 220,000$ 和 $Cost_{Q2}=R_1C_G + R_1S_GC_J = 250,000$,那么应当选择 Q1 作为最优查询计划。
但是在分布式条件下,我们需要考虑数据的分布情况。因为 T2 是在 T2.a 上进行分片的,但是 T1 却不是在 T1.a 上分片的,所以我们需要将 T1 进行 reshuffle 或者对 T2 进行广播(broadcast)。假设 T2 跟 T1 差不多大,那么对 T1 进行 reshuffle 代价是更小的。对于 Q1 来说,在 join 之后进行 group by 不需要进一步移动数据,因为 join 的结果就是根据 T1.a 分布的;对于 Q2 来说,在 join 之前进行 group by 也不需要移动数据,因为数据是根据 T1.b 进行分布的。因此,在执行时 Q1 会先对 T1 根据 T1.a 进行 reshuffle,再在每个分片上执行 join 和 group by;Q2 则会先在每个分片上执行 group by,再将 group by 的结果进行 reshuffle,最后在每个分片上和 T2 做 join。Q1 和 Q2 的执行计划就成了:
1 | |
假设在网络中移动一条数据的代价是 $C_R = 3$,那么两个查询的代价则会变成 $Cost_{Q1} = R_1C_R + R_1C_J + R_1S_JC_G = 620,000$ 和 $Cost_{Q2} = R_1C_G + R_1S_GC_R + R_1S_GC_J = 400,000$,Q2 成了更好的那一个计划。可见在分布式环境下,数据通过网络的开销会成为查询代价里的主要部分。作者在亚马逊 EC 集群上做的实验表明,执行 Q2 比执行 Q1 要快 2 倍。如果查询优化器没有将分布式代价计算到查询代价里,那么就会错误地选择 Q1 作为最优代价。
浓密连接
在对 join 的连接进行搜索时,如果需要考虑各种各样的组合,那么搜索空间就会变得非常大,效率比较低。因此,一些数据库的优化器限定只考虑左深树(例如 System-R,MySQL)或者右深树来减小搜索空间。但是在一些涉及到多个星型模型或雪花模型的查询中,浓密连接(Bushy Join)比左深树或者右深树的执行效率更高。一般来说,对于 Join 顺序的确定都是在对逻辑计划向物理计划转换时完成的,对于 MemSQL 来说则是在 Enumerator 完成这一工作。MemSQL 的 Enumerator 只能生成左深树的查询计划,为了在查询计划中加入浓密连接,MemSQL 在 Rewrite 阶段通过启发式规则将多个表结合成一个 derived table 加入到查询树中。
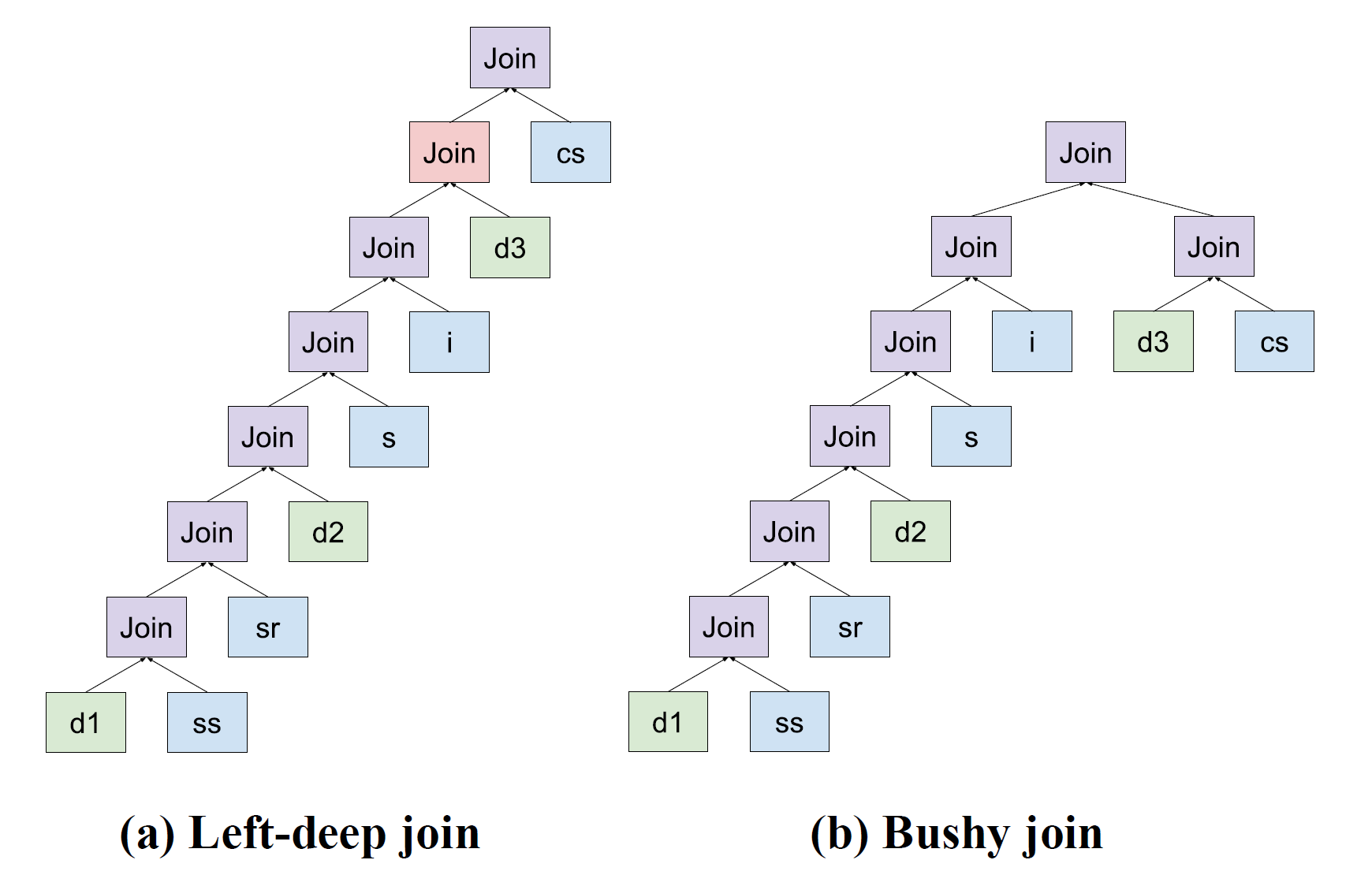
MemSQL 引入 Bushy Join 的方法是先构建连接图(Join Graph),然后在从连接图中寻找卫星表(satellite table)和种子表(seed table),再将种子表以及其关联的卫星表转化为一个 derived table 加入到查询树中。具体的算法如下:
1 | |
在上面这个过程中,产生出的派生表会被当作一个表加入到左深树中,每个派生表内部也是一个左深树,在全局上就形成了 Bushy Join。这个算法不需要获取表的基数或者谓词的选择率,只是通过连接图就可以找到可以被提取成派生表的地方。(Note:这里其实我有点没懂,在计算 Cost 的时候应该也是需要表的 cardinalities 和谓词的选择率的吧?)
论文中对这个算法举的例子来自于 TPC-DS 的第 25 个查询:
1 | |
这个查询的连接图为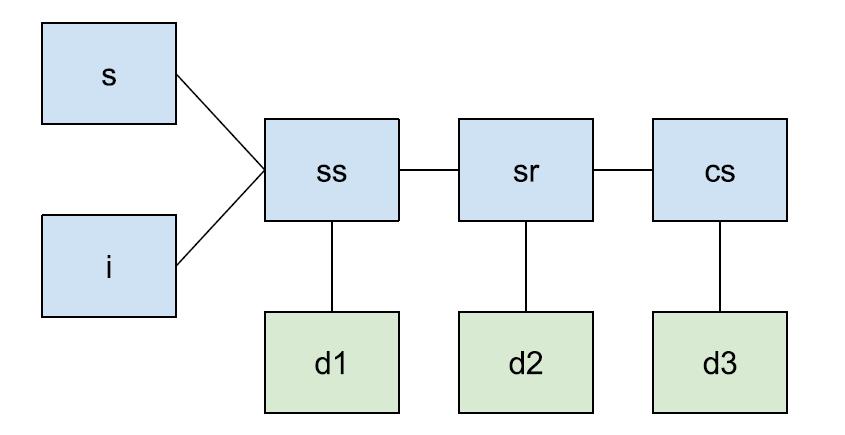
其中, ss、sr、cs 是事实表,和它们对应的维度表连接后被一个谓词过滤。在分布式环境下,最优的左深树如图 2(a) 所示。所有的 join 都有连接谓词,除了 d3,因为 d3 只和 cs 有连接谓词。所以在连接到 d3 时,就会产生一个笛卡尔积,其代价是非常高的。但由于只能使用左深连接树,比起先连接 cs,由于 d3 有一个单表过滤条件,先连接 d3 会更好。
在运行浓密连接的选择算法时,先找到候选卫星表 {d1, d2, d3},再找到卫星表,也是 {d1, d2, d}。然后再找种子表,分别是 {ss, sr, cs}。然后重写器尝试把这些表整合成派生表加入到查询树中,并计算每种组合的代价,最后得到代价最小的查询树如图 2b 所示,对应的查询语句为:
1 | |
Enumerator
搜索过程
枚举器(Enumerator)负责连接重写器(Rewriter)和规划器(Planner),它接收重写器输出的查询操作树,然后确定查询的执行计划,包括分布式环境下数据的移动和 join 的顺序。重写器主要负责逻辑优化,而枚举器主要负责物理优化。MemSQL 的枚举器基于一个假设:将最优的串行计划做并行化并不能得到一个足够好的分布式查询计划。这个假设可以在上一节所举的例子中得到验证。因此枚举器在优化时需要考虑代价、表、网络、查询特性等等因素。枚举器其中一个关注点就在于,如何尽可能利用数据的共位连接(co-located join)以降低将数据在不同节点间传递的代价。同时,MemSQL 的枚举器需要考虑如何更好地优化同时涉及到行存和列存数据的查询。
MemSQL 的枚举器在优化时只会在一个 Query Block 里面进行优化,而不会把一个查询块里的 join 移动到另一个查询块上执行(个人理解这个操作属于逻辑优化,应该在 Rewrite 阶段通过启发式规则或者基于代价的规则完成,在 Enumerate 阶段就假设能做的都已经做完了)。在优化时采用自底向上的方式,从最小的 Expression 开始优化,再优化该表达式的上层表达式(例如对于一个嵌套查询,先优化内层的子查询,再优化外层的查询)。当最外面的一层查询被优化完后,枚举器的优化过程就结束了。
由于分布式条件下可能会涉及到不同节点间的数据移动,搜索空间会比单机查询优化的空间更大。为了限制搜索空间的大小,MemSQL 的优化器像 System-R 优化器一样,实现了一种带有 interesting properties 的动态规划算法。在 System-R 中,interesting properties 主要是算子的输出是否有序。在 MemSQL 中,interesting properties 主要是数据的分片。在进行等值 join 或者分组操作时,shard key 可能就会带来一些帮助。
分布式代价计算
论文还介绍了一下计算分布式代价的公式,主要包括两个操作:广播(Broadcast)和分区(Partition)。前者指的是把数据传输到每个节点上,后者指的是把每个执行节点上的数据根据指定的分区键进行重新分布(reshuffle)。广播的代价为 $R \times D$,分区的代价为 $\frac{1}{N}\times(R\times D + R\times H)$,其中 $R$ 是需要移动的数据行数,$D$ 是移动每行数据所需要的代价,$N$ 是集群中节点的个数,$H$ 是对每行数据计算哈希值的代价。
Planner
规划器(Planner)负责将枚举器输出的物理操作树变成分布式执行计划。执行计划由多个 DQEP Step 组成,每个 Step 都可以用类似 SQL 的文本表示。当调度节点将计划分发到每个执行节点上时,传输的内容就是一条条像 SQL 一样的文本。论文中解释这是因为 SQL 非常容易理解,并且使用 SQL 还可以在每个执行节点侧进行节点级别的优化和拓展。
Result Table 和 Remote Table
为了支持使用 SQL 描述 DQEP Step,MemSQL 为 SQL 增加了两个拓展:Remote Table 和 Result Table。
当一个查询需要让一个节点访问所有节点的数据时,就可以使用 Remote Table 关键字。例如下面这个 SQL
1 | |
其中 REMOTE(facts) 表明 facts 表中的数据不仅来源于本地的数据分区,还来自于集群中的其他节点。
当一个集群中的所有节点都使用 Remote Table 访问数据时,很多工作会被重复多次,例如数据可能会被读或者计算多次。为了节省计算量,MemSQL 使用 Result Table 来让每个节点在本地保存一个临时表,表里的数据全部来源于本地分区。例如下面这个 SQL 就在每个节点上都创建了一个名为 facts_filtered 的表,每个节点上的 facts_filtered 表只包含自己本地 facts 表的数据。
1 | |
对 DQEP 的描述
DQEP 中涉及到很多对数据的移动和计算,这些都需要使用 SQL 表示出来。在 MemSQL 中,这是通过在 Result Table 内将这些操作连接起来实现的。DQEP 的每个阶段都由一个计算步骤表示,这个计算步骤会从上一个执行步骤中拉取数据,中间结果会用 Result Table 保存。Resul Table 不需要被物化,可以在执行时流式地进行计算和传递结果。
Broadcasts 的表示
假设有这样一条 sql:
1 | |
如果 x 是根据 a 进行分片的而 y 不是,那么我们要么 reshuffle y 要么就广播 x。假如经过计算我们认为广播 x 代价更低,那么整个 DQEP 可以表示为
1 | |
其中(1)在每个分区本地执行;(2)在每个节点执行,但是需要读取其他分区的 Result Table r1;(3)在每个分区执行,执行后将结果传输到调度节点汇总生成最后的结果。因为 Result Table 可以流式地创建和传输,因此整个查询执行时就是流式的。在执行(2)时,x 的数据就会被广播到整个集群。
Reshuffle 的表示
还是前面那个查询,假如我们要 reshuffle y,那么 DQEP 可以表示为:
1 | |
(1)将 y 中的每一行都根据 a 进行了重新分区。(1)完成后 x 和 y 都是根据 a 进行分片的,因此(2)可以在每个分区本地执行,然后将结果汇总到调度节点中。如果 x 和 y 都不是根据 a 进行分区的,那么可以对 x 和 y 都 reshuffle:
1 | |
总结
MemSQL 的查询优化器总体上就是 Rewrite + Physical Optimization + Plan Distribution。其中在 Rewrite 不仅使用了启发式规则,还使用了基于代价的规则,和 Oracle 的 CBQT 有点像。通过启发式规则在仅支持左深树的 Enumerator 的基础上引入 Bushy join 这一点比较特别。在物理优化时要考虑数据的分布和移动的情况,否则可能生成出较差的查询计划。在分发查询计划时,使用 SQL-like 的文本进行传输而不是将查询计划序列化之后分发,这一点是也是比较特别的。